SuperPrompt - Better SDXL prompts in 77M Parameters


Left: Drawbench prompt "A rainbow penguin in a tuxedo". Right: SDXL output with SuperPrompt applied to the same input prompt.
TL;DR: I've trained a 77M T5 model to expand prompts, and it meets or exceeds existing 1B+ parameter LLMs in quality and prompt alignment.
When DALL-E 3 was released, I was a) really impressed, and b) struck by how obviously good an idea the prompt augmentation it uses was. To that end, I've spent some time over the last few months playing around with some various approaches to emulate that functionality.
When viewed from a more general perspective, the problem of "take a user's intent, and generate an image that looks better than it would otherwise", without tuning the T2I model itself, has some interesting potential upsides:
- When tuning a model for aesthetics, it's very easy to overfit in strange ways; for example, biasing towards heavily saturated imagery, or smoothing out details; this leads to a model that can't reproduce those qualities when you want them to. An initial upsampling step leaves the original model intact but potentially gives the same benefits.
- Large models have biases, that are notoriously hard to remove or tune. OpenAI partially solves this with the ChatGPT system prompt, which has lots of instruction related to content policy, protecting IP, etc. Changing a system prompt is much cheaper than tuning a T2I model!
- Eventually, more T2I models will get better at following text prompts, like DALL-E 3 is; however, a lot of users (myself included) will still want to prompt for simple things like "a dog in a bucket hat", whereas the model is conditioned to generate images with captions like "A cute, fluffy dog wearing a colorful bucket hat. The dog is sitting in a sunny garden, surrounded by vibrant flowers. The hat is tilted slightly to one side, adding a playful touch to the dog's appearance." Just asking for a "a dog in a bucket hat" leaves a lot of potential detail and fidelity on the table!
So here are the approaches I tried:
CLIP augmentation
The idea here is that the existing model (in my experiments, SDXL 1.0) is conditioned on CLIP text embeddings; and within a CLIP embedding space, the existing prompt, and a better prettier prompt, both exist - so I'd train a ~20M parameter MLP to convert the CLIP embeddings (unpooled, as is used in the diffusion model) from an worse looking prompt to a nicer one. For the dataset, I'd use the DiffusionDB prompt dataset, and use Llama2 to rewrite the prompts to remove any descriptors that might improve the fidelity of the image.
| Input | Target |
|---|---|
| beautiful porcelain biomechanical cyborg woman, close - up, sharp focus, studio light (...) | porcelain cyborg woman |
| two scientists wearing red high fashion hazmat suits in a glowing geometric nebula wormhole tunnel (...) | two scientists wearing red hazmat suits in a tunnel |
Example rows from the dataset.
This didn't work; I tried a number of things, from various model architectures / configs to different datasets and augmentation pipelines. The model would get frustratingly close at times; I'd watch it generate a much nicer or more coherent scene for one sample and totally whiff it with the next. I think there's potentially a solution here, but it might require some very sensitive hyperparameter tuning to avoid overfitting or model collapse. The existence of aesthetic predictors and other classifiers built atop CLIP implies that this should be possible, though such models don't have to account for the biases that the diffusion model contains towards the text encoder.


Left: baseline with prompt "A yellow colored giraffe" from Drawbench. Right: SDXL output with CLIP-augmented text embeddings.
U-Net augmentation
Thinking about why the CLIP augmenter didn't work, I wondered if it might be easier to instead augment the latent during certain steps of the denoising process. Taking a page from SD Ultimate Upscale - which uses a secondary U-net to upscale a latent - I tried training a latent augmenter, while performing inference on prompts from the same DiffusionDB dataset.


Left: baseline with prompt "A white sheep driving a red car" . Right: SDXL output with Unet augmentation pass before sampling.
This did seem to work, though the U-net was fairly big - about 800M parameters, which is nearly the size of the smallest LLMs; and the results were still not great. It felt like the improvement in quality wasn't really worth how big the model was; as is often the case in ML, it's likely there is a way to get this to work well - though it might require a dataset or training regime that is radically different from what I tried. I spent a few weeks fiddling with this, before finally realizing I wasn't really making progress; and anyways, this approach has a few serious downsides:
- When VAE or model architecture changes happen, the model would have to be at best tuned heavily, and at worst, trained again from scratch.
- The model needs lots of data to train, as we're training a U-net from scratch. Decent quality output only started to appear after about 100k steps, and the model was still improving at 200k steps. Besides cost, this is also a fairly large-scale aesthetic dataset; even Pick-a-Pic which is ~600k samples would likely not be large enough.
You know what doesn't have these issues? Language models.
TinyLlama
As I was working on this, the first few TinyLlama Instruct checkpoints had been released. It seemed like a good fit; take the existing prompt dataset, reformat it to be compatible with Axolotl, and tune. Fortunately, this worked, almost immediately!


Left: generated with the prompt "A white sheep driving a red car" . Right: generated with the upsampled prompt "a fluffy white sheep confidently drives a shiny red car along a scenic country road".
In fact - without any tuning the instruct model did a pretty good job of expanding prompts. However, thinking back to earlier projects like MagicPrompt, and how well that model performs with a fifth of the parameters (200M in GPT-2 vs 1B), it's actually a lot less impressive. To that end, I started looking at options for going smaller.
Sequence to Sequence
The smallest T5 model available is 22 million parameters; for BERT, about 8 million. These are absurdly tiny for 2024 language model standards; roughly the same size as the MLP layers we used above! After writing some basic training code, I fine-tuned a 77M T5 model using the same augmented DiffusionDB dataset as above, and got prompts like:
a fleet, 8 k, starships, oil painting, detailed, cyberpunk colour palette, composition, lighting, masterpiece, by adrian ghenie and jenny saville and zhang jingna
Promising - though not perfect. Cue more hyperparameter tuning, fixing implementation details in my training script, etc - before finally digging into. While this dataset was large - about 5 million rows - I was beginning to suspect that the augmentations and the quality of the data itself was limiting things; it included lots of prompts like this:
mount epic mechanical dragons steamscale incinerator screenshot world of warcraft mounts worldboss, art gta 5 cover, official fanart behance hd artstation by jesper ejsing, by rhads, makoto shinkai and lois van baarle, ilya kuvshinov, ossdraws, that looks like it is from borderlands and by feng zhu and loish and laurie greasley
and this:
gundam head, v - fin, octane render, soft light, mekka, behance, vector, highly detailed illustration, realistic, black and gold metal design, dribbble. com, by secondsyndicate studio,
Which are nearly entirely adjectives, and when filtered by the LLM, return maybe 1-2 words out of a 30-40 word prompt. This means that the model would have to associate lots of adjectives to relatively few subjects / nouns. So I tried a different strategy - generating synthetic hyper-detailed prompts following the upsampling prompt in the DALL-E 3 paper, and the PartiPrompts dataset. Cue another training run on flan-T5-small, and we get prompts like:
The storefront of "Hello World" is painted in vibrant shades of orange and yellow, with the words "Hello World" written in bold, cursive letters across the front. The storefront is surrounded by a bustling cityscape, with skyscrapers and neon signs lining the walls. The storefront is surrounded by a sea of people, all gazing up at the sky with a sense of excitement and excitement.
In the tranquil expanse of a picturesque countryside, where rolling green hills meet the azure sky, a fluffy white sheep confidently takes the helm of a shiny red car, navigating its way along a winding road with an air of determined curiosity and adventurous spirit.
Amazing! And the resulting images look great too.




The trained model is now available on my HuggingFace page - download it here, and try adding it to your pipeline with the Transformers library, like so:
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small")
model = T5ForConditionalGeneration.from_pretrained("roborovksi/superprompt-v1", device_map="auto")
input_text = "Expand the following prompt to add more detail: A storefront with 'Text to Image' written on it."
output = model.generate(tokenizer(input_text, return_tensors="pt").input_ids.to("cuda"))
I'll also be publishing a ComfyUI custom node, and some more variant models, soon.
Takeaways
The data is the most important thing. No model architecture, especially with smaller models, can correct for data that is fundamentally flawed in some way. I could have saved myself lots of time hopping between different model architectures and tweaking hyperparameters if I'd started with a cleaner, smaller dataset, and started with the simplest approach first. Again - something I've learned many times over, but it's still all too easy to reach for a shiny new architecture instead of reviewing data.
Taking a very general problem like this and tackling it by training models is a tough process, but I always learn a lot by doing so; and hopefully you learned something from this post, or use the resulting model to generate better images.
Evaluation and Notes
- Evaluation results are below; both were gathered on the Drawbench dataset. This uses the CLIP distance of the generated image with SDXL, at 40 steps and the Euler sampler, from the original prompt as the metric. You can see how wide of a gulf there is between the U-net and CLIP aug methods, and the LLM-based methods.
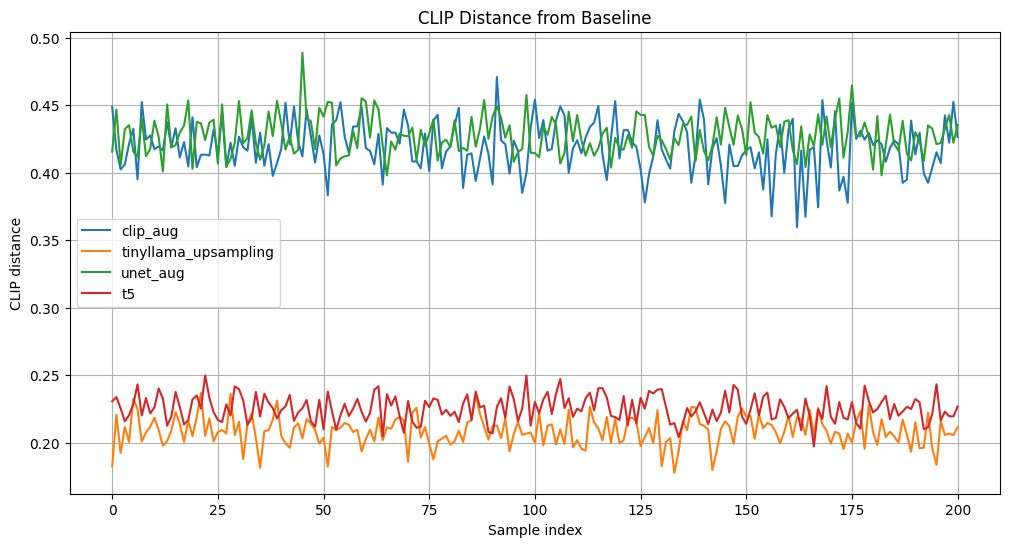
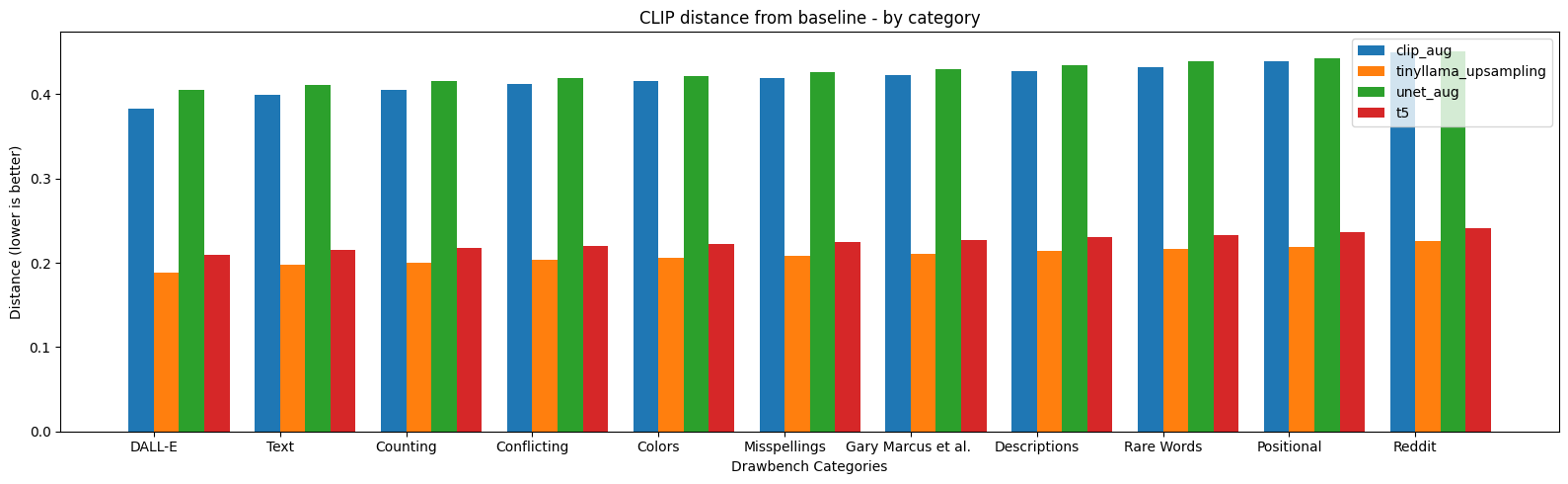
- With T5 fine-tuning, the common recommendation is to use Adafactor as an optimizer. Suprisingly, I found that AdamW worked better in my experiments; I suspect this is more to do with learning rate schedule, which I kept both longer and less aggressive than the recommended defaults, which meant that the aggressive beta updating Adafactor is meant to combat don't appear in my experiments.
- You can find the rest of the code for prompt upsampling, and the other experiments in this repo. Be warned, it's not very clean!
- I filtered Drawbench for any overlap with my augmented dataset, and performed a basic deduplication (n-gram overlap) on the augmented dataset prior to training. The model only works in English, but shouldn't be hard to adapt to other languages. It also has a tendency to repeat itself when generating for long enough but I didn't observe this happening at or below the 77-token limit for SDXL prompts.
Disclaimer: I work at Stability AI, but all work mentioned here is a personal side project and isn't affiliated with Stability in any way.